My solution at ISCSO 2016 and meta optimisation
Two years ago, I participated in ISCSO (International Student Competition in Structural Competition), a competition on structural optimisation. However, I didn’t submit my solution that time because I didn’t reach the target set by the organiser. After reading some literatures about optimisation, especially Bayesian Optimisation, I participated again in ISCSO this year and won. This post is about the approach I used in the competition.
Problem
Even though the competition is about structural optimisation, no prior knowledge on structure or civil engineering required. The organiser sets up a MATLAB function to do all the civil engineering calculations. The participants just need to find the right parameters and read the output.
This year’s problem is about cantilever. The topology of the cantilever is fixed, but the \(z\) position of some points and sizes of every truss are to be optimised. The topology is shown by the picture below (credit to:http://www.brightoptimizer.com/).
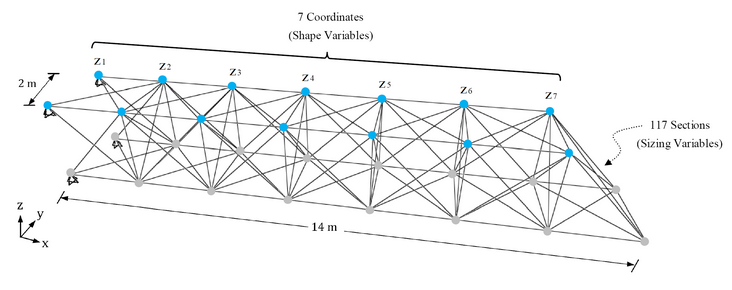
The objective is to minimise the weight of the total structure without violating two constraints (i.e. maximum displacement and maximum stress). Fortunately, the organiser has set up a MATLAB function below.
[Weight, Const_Vio_Stress, Const_Vio_Disp] = ISCSO_2016(Sections, Coordinates, 0);
Sections is a \(1 \times 117\) vector with each element is an integer from 1 to 37.
Coordinates is a \(1 \times 7\) integer vector with value between 1000 to 3500.
Const_Vio_Disp and Const_Vio_Stress are two constraints that has to be zero in the final design.
Weight is the weight of the structure. This is the output to be minimised in the optimisation.
CMA-ES
There are 124 variables in total to be optimised and they are all integers. It also means the optimisation algorithm needs to search for the optimum design in 124 dimensions search space. A lot of optimisation techniques are available, but for a hundred dimensions, it seems that a lot of people use CMA-ES. CMA-ES is also used in Bayesian Optimisation to optimise the surrogate function.
In CMA-ES, a user specifies an initial position as the centre point in the search space and standard deviation for each dimension. The algorithm then generates a number of points around the centre point based on normal distribution with the corresponding standard deviation. All generated points are evaluated and it chooses the best half of the population. It then updates the centre point based on the mean position of the best half of the population and the previous centre points. Not only that, the algorithm also updates the covariance matrix based on the covariance matrix of the best half of the population, previous covariance matrix, and the centre point. With the new centre point and covariance matrix, the algorithm generates a new population around the new centre point based on normal distribution with the corresponding covariance matrix.
This is a tutorial for CMA-ES written by N. Hansen, who came up with the idea of CMA-ES. The source code for MATLAB can also be found here. Here is a nice illustration of CMA-ES from Wikipedia.
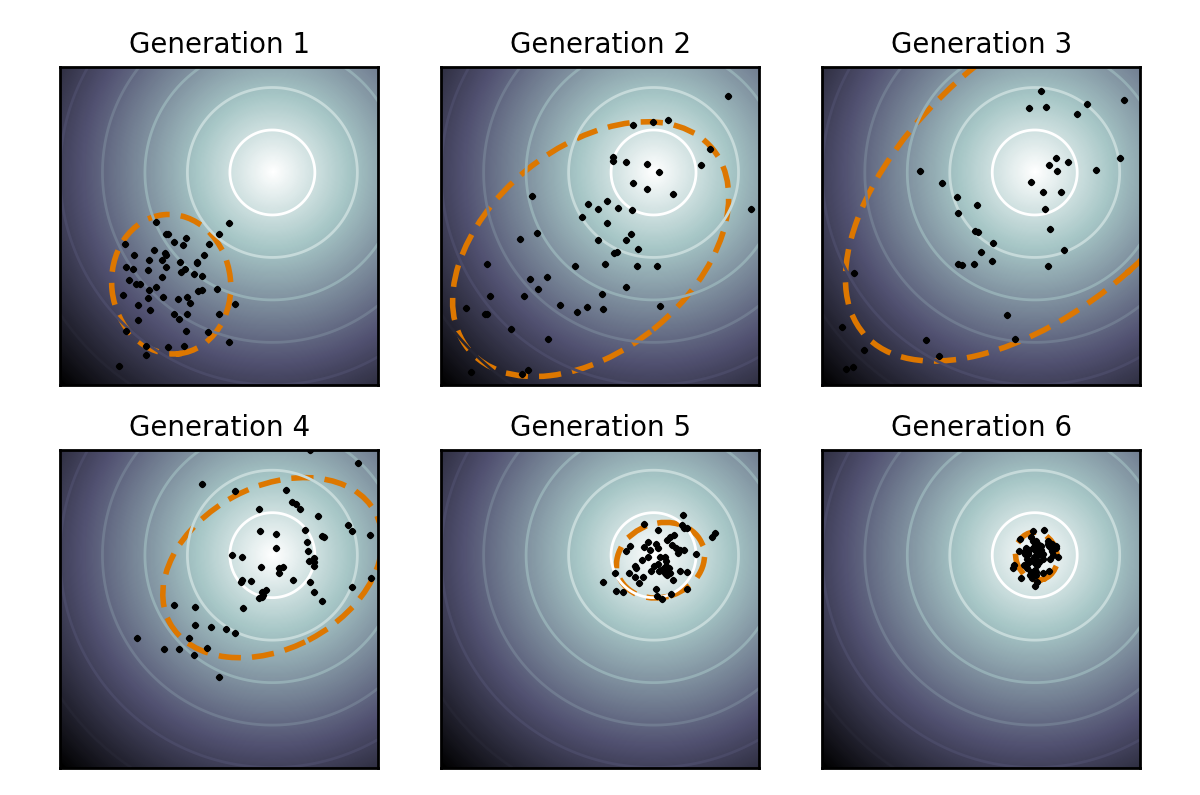
Loss function
Back to ISCSO. The objective is to find the minimum weight without violating the two constraints. My first step is to set a loss function as
\[L = w + \lambda_1 c_1 + \lambda_2 c_2 + \lambda_3 (c_1 + c_2 > 0),\]where \(w\) is the weight, \(c_1\) and \(c_2\) are the first and the second constraints, respectively, and \(\lambda_i\) are variables for the penalty terms. The fourth term on the right hand side of the equation is necessary to make sure that both constraints are zero. Without this term, \(c_1\) and \(c_2\) can take a very small number to reduce the penalty.
Meta-optimisation
Setting \(\lambda_1 = \lambda_2 = \lambda_3 = 1000\) arbitrarily, I tried to minimise the loss function using CMA-ES. CMA-ES has several tunable parameters, but the author suggested default values for every tunable parameters. Using CMA-ES with the default values of its parameters, I got the weights around 3200-3400. Running it longer did not improve much. However, there are 11 variables yet to be tuned for the CMA-ES.
I was thinking to use Bayesian Optimisation, but Bayesian Optimisation works great for moderate dimensions (less than 10). The other option is to use another CMA-ES to tune the CMA-ES. This process is called as meta-optimisation, which is optimising the optimiser.
The result is surprising. Now the optimiser can get the weights around 2800-2900 consistently. Before optimising the optimiser, our optimiser was hardly went below 3100, but now it is consistently reach 2800-2900. To get the best results, I run it several times. There I got my best result shown in the website (i.e. 2816).